Automated Data Extraction and Processing System ⚙️
Project Overview 📖
This project focuses on the automation of unstructured data processing pipelines using artificial intelligence and workflow orchestration. It was conducted as part of my supervision with my intern in Data Engineering and Decision Systems.
The system ingests heterogeneous raw data sources, applies AI/NLP models for information extraction, runs automated validation checks, and continuously feeds structured outputs into real-time dashboards. This ensures a scalable, reliable, and low-latency pipeline, significantly reducing the need for manual intervention.
Objectives 🎯
- Automate the ingestion and transformation of large-scale unstructured datasets.
- Apply AI-based extraction models to parse and structure key information.
- Ensure data reliability through automated quality control mechanisms.
- Deploy pipelines using scalable and reproducible technologies.
- Provide interactive visualization through continuously updated dashboards.
Approach and Methodology 🔬
1. Data Ingestion 📥
- Automated collection from multiple heterogeneous sources.
- Handling of different formats (PDF, CSV, scraped text).
2. Information Extraction 🤖
- Utilized NLP techniques to extract relevant fields.
- Integrated custom parsing models for complex document structures.
3. Data Validation ✅
- Implemented automated anomaly detection and consistency checks.
- Applied rule-based and statistical methods to enforce data quality.
4. Storage & Processing 🗄️
- Structured datasets stored in relational databases.
- Optimized schema design for efficient querying and integration.
5. Visualization 📊
- Processed outputs automatically streamed to Power BI dashboards.
- Interactive exploration enabled for monitoring and analysis.
6. Workflow Orchestration & Deployment 🚀
- Apache Airflow used for scheduling and monitoring pipelines.
- Docker employed for containerization and reproducible deployments.
Results & Outcomes 🏆
- Fully automated pipeline for unstructured data processing.
- Reliable data quality verification reducing errors and inconsistencies.
- Real-time dashboards ensuring continuous access to updated datasets.
- Modular design enabling scalability and adaptability to new sources.
Future Directions 🔮
- Optimize parsing algorithms to handle more complex document structures.
- Improve processing speed and throughput via script optimization.
- Extend workflow modules to integrate additional data types and formats.
- Enhance monitoring with advanced logging and alerting systems.
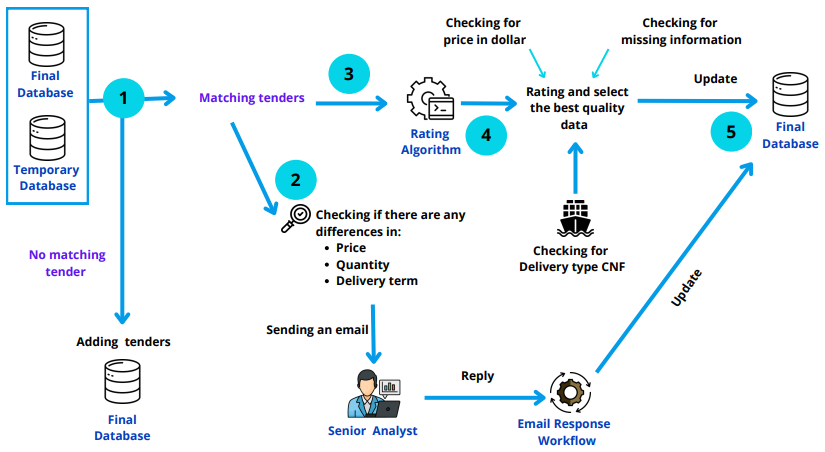
Visual Examples 📸
Pipeline Architecture
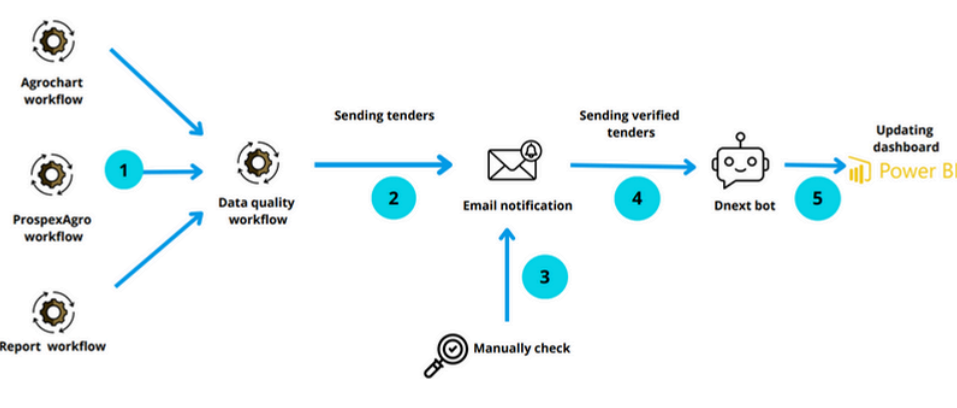
Data Quality Process Check